مدلهای یادگیری ماشین خیلی وقتها به چشم یک جعبه جادویی نگاه میشن که با دادهها کار میکنن و کلی نتایج شگفتانگیز بیرون میدن. اما این مدلها برای این که بتونن پیشبینیها و تصمیمگیریهای دقیق انجام بدن، باید حسابی آموزش ببینن و بعد از آموزش هم باید مطمئن بشیم که تو دنیای واقعی خوب کار میکنن. اینجا قراره درباره ۴ روش مختلف برای تست و اطمینان از عملکرد این مدلها تو شرایط واقعی صحبت کنیم.
مدلهای یادگیری ماشین دقیقاً چکار میکنن؟
مدلهای یادگیری ماشین مثل یه مغز مصنوعی عمل میکنن که با استفاده از دادههای قدیمی آموزش میبینن و تو دل دادهها دنبال الگوها و روابط مهم میگردن. بعد از آموزش، آماده هستن که وقتی با دادههای جدید مواجه میشن، پیشبینیهای دقیقی انجام بدن. امروزه کلی از شرکتها از این مدلها برای به دست آوردن یه برگ برنده تو بازار استفاده میکنن. از شخصیسازی تجربه مشتری گرفته تا پیشبینی خرابی تجهیزات و حتی تشخیص تقلب. خلاصه که این مدلها به شرکتها کمک میکنن که سریعتر، هوشمندتر و با دقت بیشتر تصمیم بگیرن.
تست مدلهای یادگیری ماشین چیه و چرا مهمه؟
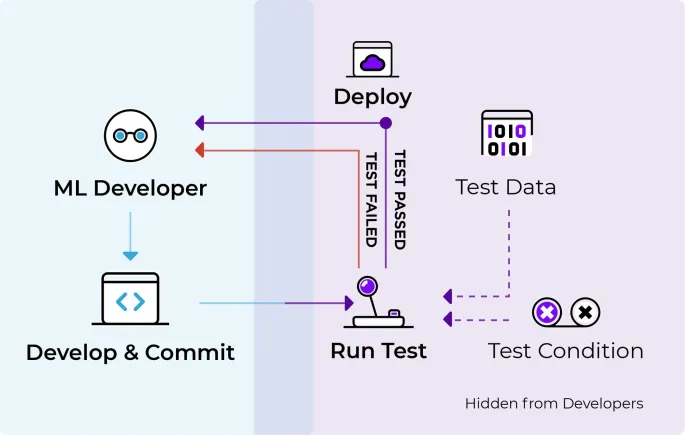
وقتی میخوایم مدلهای یادگیری ماشین رو توی فرآیندهای روزمره و محیط واقعی پیادهسازی کنیم، نمیتونیم همینطوری بذاریم برن سر کار! لازمه که قبلش کلی تست و ارزیابی روی مدلها انجام بدیم که مطمئن بشیم تو شرایط واقعی خوب جواب میدن. تست مدل شامل یه سری مراحل مشخصه که سلامت دادهها رو بررسی میکنه، از عدم تعصب اطمینان حاصل میکنه و تعاملات بین اجزای مختلف مدل رو میسنجه.
هدف اصلی از تست مدل، پیدا کردن و رفع مشکلات احتمالی و آسیبپذیریهاست. این کار باعث میشه که مدل بتونه تو شرایط مختلف و حتی تو برخورد با ورودیهای غیرمنتظره هم عملکرد خوبی داشته باشه. همین طور، تعصبهای مدل کمتر میشه و نتایج مدل قابل اعتمادتر و عادلانهتر میشه.
تفاوت بین ارزیابی و تست مدل چیه؟
ممکنه براتون سؤال بشه که ارزیابی مدل با تست اون چه فرقی داره؟ خب، ارزیابی بیشتر به کارایی کلی مدل توجه داره و معیارهای مثل دقت، یادآوری، یا خطای میانگین رو بررسی میکنه. اما تست مدل بیشتر رو جزئیات و رفتار مدل تو سناریوهای واقعی تمرکز داره، مثل اینکه آیا باگها رو مدیریت میکنه، یا آیا تعصب داره یا نه.
در واقع، تست مدل یه جور ضمانته که این مدل توی شرایط واقعی خوب کار میکنه و میشه روش حساب کرد.
برای تست مدلهای یادگیری ماشین، مثل هر کار دیگهای که اهمیت زیادی داره، نیاز به ابزارهای درست و حسابی داریم. خوشبختانه چندین فریمورک عالی هستن که کارمون رو تو این زمینه خیلی راحتتر و سریعتر میکنن. این ابزارها به ما امکاناتی میدن که مدلهامون رو به شکلی ساختاریافته و کامل تست کنیم، مطمئن بشیم دادهها و مدلها درسته، و حتی بتونیم تستها رو دوباره تکرار کنیم تا نتایج دقیقتر و قابل اعتمادتر بشه.
در ادامه میخوام به چند تا از فریمورکهای کلیدی برای تست مدلهای یادگیری ماشین اشاره کنم که توی این زمینه حرف اول رو میزنن:
TensorFlow:
تنسرفلو سه ابزار اصلی برای تست مدلها داره:
- TensorFlow Extended (TFX): این فریمورک یه پکیج کامل برای مدیریت و تست خط لوله مدلهاست. TFX امکاناتی برای اعتبارسنجی دادهها، تحلیل مدل و حتی استقرار مدلها در محیطهای عملیاتی ارائه میده.
- TensorFlow Data Validation: این ابزار مخصوص تست کیفیت دادهها طراحی شده و مطمئن میشه که دادههایی که به مدل وارد میکنیم درسته.
- TensorFlow Model Analysis: این ابزار برای تحلیل عمیقتر مدل به کار میاد و به ما اجازه میده عملکرد مدل رو از زوایای مختلف بررسی کنیم.
PyTorch:
پایتورچ با گراف محاسباتی دینامیکش، خیلیها رو جذب خودش کرده. این فریمورک ابزارهای قدرتمندی برای ارزیابی مدل، اشکالزدایی و حتی بصریسازی فراهم کرده. مثلاً torchvision که شامل کلی مجموعهداده و تبدیل برای آزمایش مدلهای بینایی ماشین هست.
Scikit-learn:
سایکیتلرن از اون کتابخونههای چندمنظوره پایتونه که خیلی از افراد برای کارهای یادگیری ماشین ازش استفاده میکنن. این کتابخونه برای ارزیابی و تست مدلهای مختلف کلی معیار و ابزار داره، از جمله اعتبارسنجی متقابل و جستجوی شبکهای برای تنظیم هایپرپارامترها. خلاصه که سایکیتلرن برای تحلیل داده، استخراج دادهها و وظایف پایهی یادگیری ماشین عالیه.
Fairlearn:
یکی از مشکلات مهم مدلها، مسئله انصاف و تعصبه. فیرلرن یه ابزار تخصصیه که دقیقاً برای ارزیابی و کاهش تعصب و افزایش انصاف طراحی شده. این فریمورک الگوریتمهایی داره که با وزندهی دوباره به دادهها یا تنظیم پیشبینیها کمک میکنه تا مدلها عادلانهتر رفتار کنن و نتایج منصفانهتری ارائه بدن.
Evidently AI:
این ابزار منبع باز پایتون به تحلیل، نظارت و اشکالزدایی مدلها در محیط تولید کمک میکنه. Evidently AI خیلی به درد کسایی میخوره که میخوان مدلهاشون رو بعد از پیادهسازی زیر نظر داشته باشن و مطمئن بشن که همه چی داره درست کار میکنه.
این فریمورکها کمک میکنن مدلهای یادگیری ماشین در محیطهای عملیاتی هم پایدار و دقیق بمونن و نتایج قابل اعتمادی ارائه بدن. پس اگه مدل خوبی ساختین، این ابزارها رو فراموش نکنید تا مطمئن بشید که تو شرایط واقعی هم عالی عمل میکنه!
۴ روش برای تست مدلهای یادگیری ماشین در محیط تولید
وقتی به بحث تست مدلهای یادگیری ماشین میرسیم، نکات و روشهای مختلفی وجود داره که میتونه خیلی مفید باشه. در اینجا میخوام به چهار تا از اصلیترین روشها که برای تست مدلهای یادگیری ماشین توی محیط تولید استفاده میشه بپردازم. این روشها به ما کمک میکنن تا مطمئن بشیم مدلهای جدید نه تنها درست کار میکنن، بلکه به بهترین شکل ممکن دارن عمل میکنن.
A/B Test:
اولین روشی که میخوام در موردش صحبت کنم، آزمایش A/B هست. این روش برای مقایسه عملکرد دو نسخه از یک مدل به کار میره و کمک میکنه بفهمیم کدوم یکی از این مدلها توی شرایط واقعی بهتر عمل میکنه. نکته مهم اینه که قبل از اینکه مدل جدید رو بهطور کامل در محیط عملیاتی قرار بدیم، مطمئن بشیم که واقعاً ارزشش رو داره. اینطوری احتمال به وجود اومدن مشکلات غیرمنتظره خیلی کمتر میشه.
چطور کار میکنه؟ توی آزمایش A/B، درخواستهایی که به مدل ارسال میشن به دو بخش تقسیم میشن. یه بخش کوچک از ترافیک میره سمت مدل جدید تا بتونیم ریسکهای احتمالی رو مدیریت کنیم. بعد، عملکرد هر دو مدل رو با استفاده از یه سری معیارهای مشخص ارزیابی و مقایسه میکنیم.
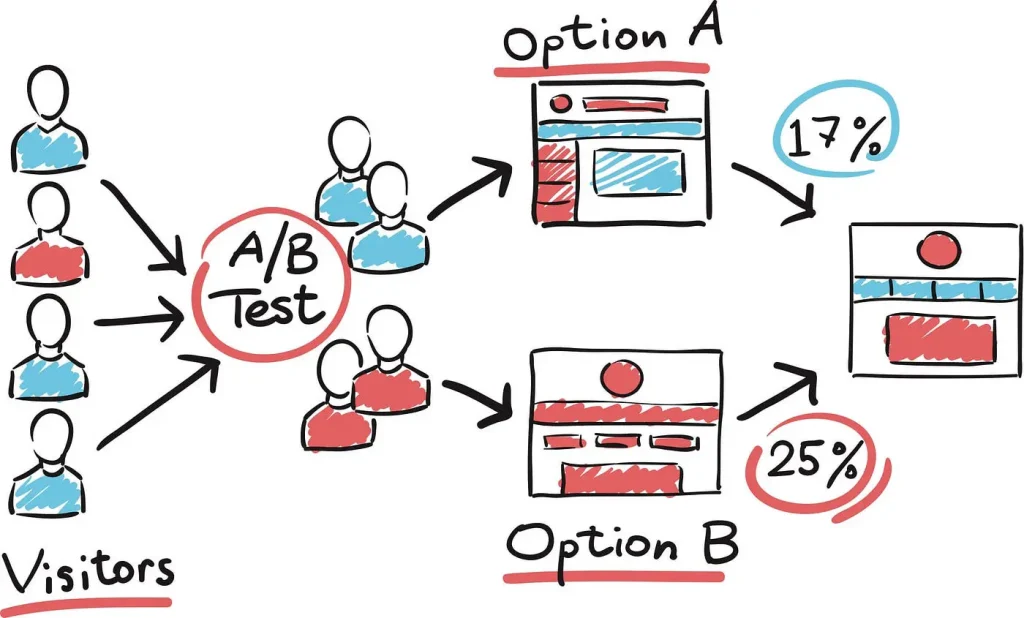
مزایای آزمایش A/B:
- کاهش ریسک: چون فقط یه بخش کوچیک از ترافیک میره سمت مدل جدید، اگه مشکلی هم پیش بیاد، تأثیرش روی کل سیستم کمتره و میتونیم بهسرعت اصلاحش کنیم.
- اعتبارسنجی عملکرد: این روش به ما نشون میده که آیا مدل جدید بهاندازه مدل قبلی خوب عمل میکنه یا بهتره.
- تصمیمگیری دادهمحور: با نتایج آزمایش A/B، میتونیم بر اساس دادههای واقعی تصمیم بگیریم که آیا مدل جدید رو بهطور کامل جایگزین کنیم یا باید تغییرات بیشتری توش ایجاد کنیم.
بنابراین، آزمایش A/B یکی از مراحل کلیدی برای تست مدلهاست. این روش کمک میکنه مدل جدید رو توی شرایط واقعی بررسی کنیم و مطمئن بشیم که کارایی و اطمینان لازم رو داره، در حالی که ریسکهای مرتبط با مدلهای آزمایشنشده رو کاهش میده.
Canary Test:
آزمایش Canary یکی دیگه از روشهای خوب برای استقرار تدریجی مدلهای جدید در محیط تولید هست. این روش به ما اجازه میده که مدل جدید رو فقط برای یه گروه کوچیک از کاربران ارائه بدیم، تا اول عملکردش رو توی یه مقیاس کوچیک تست کنیم. به این گروه کوچیک از کاربران معمولاً میگیم “گروه Canary”.
هدف اصلی: ایده اصلی اینه که اول تأثیر مدل جدید رو محدود کنیم و هر مشکلی که ممکنه پیش بیاد رو با یه تعداد کاربر محدود تست کنیم. اگه همهچیز خوب پیش بره و مشکلی وجود نداشته باشه، به مرور مدل رو برای تعداد بیشتری از کاربران فعال میکنیم.
چطور کار میکنه؟ اول، مدل جدید رو فقط برای گروه Canary فعال میکنیم. اگه مدل توی این گروه عملکرد خوبی نشون داد، مرحله به مرحله تعداد بیشتری از کاربران بهش دسترسی پیدا میکنن. این کار تا جایی ادامه پیدا میکنه که همه کاربران از مدل جدید استفاده کنن.
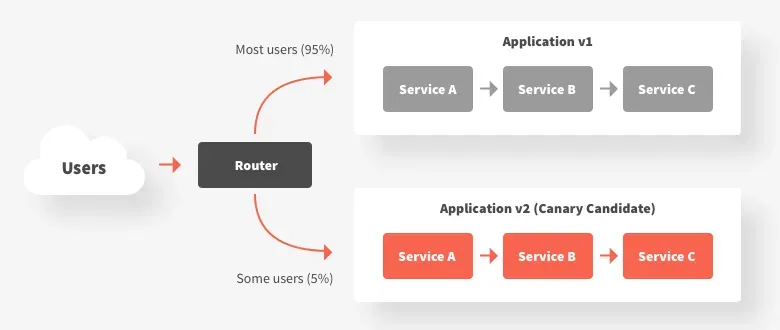
مزایای آزمایش Canary:
- کاهش ریسک: این روش به ما کمک میکنه که مدل جدید رو کمکم تست کنیم و اگه مشکلی بود، قبل از اینکه همه کاربران متوجه بشن، اون رو رفع کنیم.
- محیط کنترلشده: این رویکرد به ما یه محیط امن برای نظارت و بررسی رفتار مدل جدید میده، تا بتونیم بر اساس دادههای واقعی هر تغییری که لازمه رو انجام بدیم.
- کاهش تأثیر بر کاربران: کاربران گروه Canary نشونههای اولیه مشکلات احتمالی هستن و این امکان رو به تیم میده که سریعاً اقدام کنن و از ایجاد تأثیر منفی برای بقیه کاربران جلوگیری کنن.
بهطور کلی، آزمایش Canary یه استراتژی موثر برای استقرار تدریجی مدلهای یادگیری ماشین هست که کمک میکنه مشکلات احتمالی سریعاً پیدا و رفع بشن، در حالی که کیفیت و پایداری سرویس هم حفظ میشه.
Interleaved Test:
آزمایش Interleaved یه روش جالب برای ارزیابی چند مدل یادگیری ماشینه که بهطور همزمان خروجیهاشون رو در یه رابط کاربری یا سرویس ادغام میکنه. این روش خیلی بدرد بخوره زمانی که بخوایم بدون اینکه فقط یه مدل رو در لحظه به کاربر نشون بدیم، عملکرد چند مدل رو کنار هم مقایسه کنیم.
چطور کار میکنه؟ کاربرها بدون اینکه متوجه بشن کدوم مدل کدوم قسمت از پاسخ رو تولید کرده، با یه خروجی ترکیبی از چند مدل تعامل میکنن. این باعث میشه که بشه بازخورد دقیقتری از تعامل کاربرها و معیارهای عملکرد برای هر مدل جمعآوری کرد و توی شرایط یکسان و واقعی مقایسه کرد که کدوم مدل بهتر عمل میکنه.
معیارهای عملکرد هر مدل با توجه به نحوه تعامل کاربرها دنبال میشه. مثلاً میشه معیارهایی مثل نرخ کلیک، میزان تعامل و نرخ تبدیل رو تحلیل کرد تا فهمید کدوم مدل برای استفاده توی محیط تولید مناسبتره.
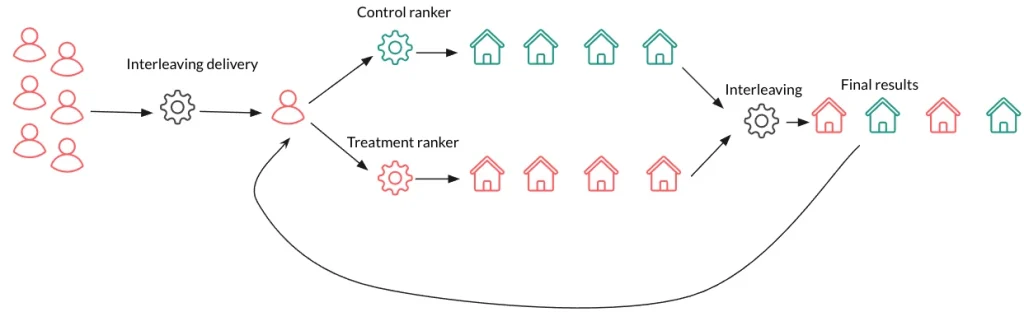
مزایای آزمایش Interleaved:
- مقایسه مستقیم: آزمایش Interleaved یه مقایسه دقیق و همزمان از چند مدل رو تحت شرایط یکسان فراهم میکنه و به ما دید عمیقتری نسبت به عملکرد هر مدل میده.
- تجربه کاربری ثابت: چون کاربر بهطور همزمان با خروجیهای هر دو مدل مواجه میشه، تجربه کاربری کلی ثابت میمونه و ریسک نارضایتی کاربر کاهش پیدا میکنه.
- بازخورد دقیق: این روش به ما بازخورد دقیقی از چگونگی تعامل کاربران با خروجیهای هر مدل میده و کمک میکنه که عملکرد مدل رو بهینهتر کنیم.
بهطور کلی، آزمایش Interleaved یه روش خیلی کاربردیه که به دانشمندای داده و مهندسین کمک میکنه تا با مقایسه دقیقتر، تصمیم بگیرن کدوم مدل رو در تولید استفاده کنن و بتونن بهترین تجربه رو برای کاربرها ارائه بدن.
Shadow Test:
آزمایش سایهای یا همون “راهاندازی تاریک” یه تکنیک جذابه برای اینکه بتونیم یه مدل یادگیری ماشین جدید رو توی دنیای واقعی تست کنیم، بدون اینکه کاربرها متوجه بشن. این روش به ما امکان میده تا دادهها و بینشهای دقیقی از عملکرد مدل جدید بگیریم بدون هیچگونه ریسکی.
چطور کار میکنه؟ توی این روش، هر دو مدل جدید و قدیمی بهصورت همزمان اجرا میشن. برای هر درخواست ورودی، دادهها به هر دو مدل ارسال میشه؛ هر دو مدل پیشبینیهایی رو تولید میکنن، اما فقط خروجی مدل قدیمی به کاربر نشون داده میشه. پیشبینیهای مدل جدید بهصورت مخفی ثبت میشن و بعداً برای تجزیه و تحلیل عملکرد مدل جدید مورد بررسی قرار میگیرن.
این پیشبینیها با نتایج مدل قدیمی و دادههای واقعی مقایسه میشن تا عملکرد مدل جدید بهتر ارزیابی بشه.
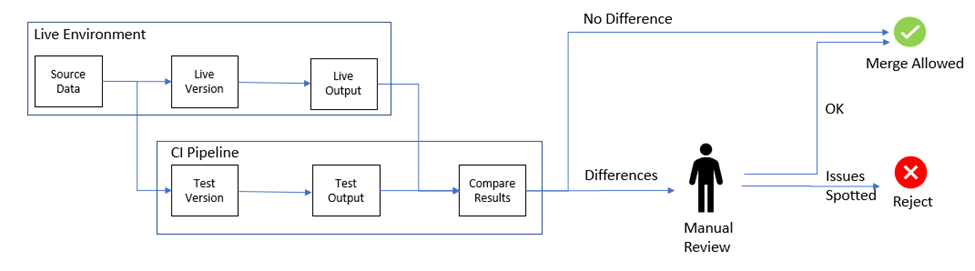
مزایای آزمایش سایهای:
- ارزیابی بدون ریسک: چون نتایج مدل جدید به کاربر نشون داده نمیشه، اگر مشکلی هم وجود داشته باشه، هیچ تأثیری روی تجربه کاربری نداره. به همین خاطر، آزمایش سایهای یه روش امن برای بررسی مدلهای جدیده.
- دادههای واقعی: این آزمایش به ما این امکان رو میده که در شرایط واقعی عملکرد مدل رو بررسی کنیم، که خیلی دقیقتر از تستهای آفلاینه.
- معیارگذاری: این روش یه فرصت عالی برای مقایسه مستقیم مدل جدید با مدل قبلیه و کمک میکنه تا نقاط ضعف و قوت مدل جدید رو شناسایی کنیم.
آزمایش سایهای یه راه مطمئن برای آزمایش مدلهای جدید یادگیری ماشینه که به ما کمک میکنه بدون تأثیر روی کاربران، عملکرد مدل رو بهطور کامل ارزیابی کنیم و برای تصمیمگیری بهتر درباره استقرار مدلها اطلاعات ارزشمندی بهدست بیاریم.
توی پست بعدی در مورد اینکه چطوری یکی از این آزمایشها رو انتخاب و استفاده کنیم حرف میزنم.
.svg )




.svg )
.svg )