20 اردیبهشت, 1404
کاهش ریسک در نوسازی سیستمهای اصلی: یک رویکرد جامع
نوسازی سیستمهای اصلی (Mainframe)، بهعنوان یکی از چالشهای مهم در دنیای فناوری اطلاعات، همواره مورد توجه متخصصان و مدیران قرار دارد. سیستمهای اصلی، که بهعنوان قلب تپندهی بسیاری از سازمانها عمل میکنند، به دلایل مختلفی مانند نیاز به بهروزرسانی فناوری، بهبود کارایی و کاهش هزینهها، نیاز به نوسازی دارند. اما این فرآیند میتواند با ریسکهای قابلتوجهی همراه باشد. در این مقاله، به بررسی استراتژیهایی میپردازیم که میتواند به کاهش این ریسکها کمک کند و نوسازی را به یک فرآیند موفق تبدیل کند.
مقدمه
با افزایش نیاز به تکنولوژیهای نوین و رقابت در بازار، سازمانها دیگر نمیتوانند به سیستمهای قدیمی و ناکارآمد متکی باشند. نوسازی سیستمهای اصلی نهتنها به بهبود عملکرد و کارایی کمک میکند، بلکه به سازمانها این امکان را میدهد که بهروزتر شوند و خود را با تغییرات بازار وفق دهند. اما نوسازی سیستمهای اصلی بهخودیخود میتواند با چالشهایی همراه باشد. از جمله این چالشها میتوان به از دست دادن دادهها، عدم تطابق در عملکرد و مشکلات ناشی از بازنویسی کدها اشاره کرد. بنابراین، درک عمیق از سیستمهای فعلی و برنامهریزی دقیق برای نوسازی آنها میتواند به کاهش این ریسکها کمک کند.
در این مقاله، به بررسی استراتژیهای مختلف برای کاهش ریسک در نوسازی سیستمهای اصلی خواهیم پرداخت. این استراتژیها شامل شناسایی نیازهای پنهان، برنامهریزی مرحلهای، تست و اعتبارسنجی دقیق، برنامهریزی برای بازگشت به حالت قبل و آموزش و انتقال دانش به تیمها است. با پیروی از این رویکردها، سازمانها میتوانند نوسازی موفقی را تجربه کنند که نهتنها به بهبود عملکرد سیستمها کمک میکند، بلکه اعتماد کاربران و ذینفعان را نیز جلب میکند.
شناسایی نیازهای پنهان از طریق مصاحبه با ذینفعان
یکی از اولین مراحل در نوسازی سیستمهای اصلی، شناسایی نیازهای پنهان است. این کار میتواند از طریق مصاحبه با توسعهدهندگان با تجربه، معماران سیستم و کاربران کلیدی کسبوکار انجام شود. بهعنوانمثال، پرسیدن از آنها دربارهی چگونگی عملکرد سیستم فعلی و مشکلاتی که در گذشته با آن مواجه شدهاند، میتواند دیدگاههای ارزشمندی را به همراه داشته باشد.
این مصاحبهها میتوانند داستانهای جنگی از تیمهای عملیاتی را به همراه داشته باشند که بهطور غیرمستقیم، نیازهای مهمی را شناسایی میکنند. بهعنوان مثال، ممکن است یکی از اعضای تیم عملیاتی داستانی از بروز مشکل به دلیل شناسههای منفی تراکنشها تعریف کند که نیاز به نصب یک افرونه در سال 1400 برای جلوگیری از این مشکل داشته است. اینگونه اطلاعات میتواند به شناسایی الزامات ضمنی کمک کند که باید به سیستم جدید منتقل شوند.
بازسازی مستندات
در صورتی که مستندات رسمی ناقص یا قدیمی باشد، بازسازی آنها یک ضرورت است. حتی یک ویکی ساده یا یک مخزن از یافتهها که شامل برنامهها، عملکرد آنها و ورودی/خروجیهای نمونه باشد، میتواند بهعنوان یک نجاتدهنده عمل کند. تشویق تیم به مستندسازی در حین یادگیری نیز بسیار مهم است. این مستندات نهتنها راهنمایی برای توسعه فراهم میکنند، بلکه بهعنوان یک مرجع در تست و نگهداریهای آینده نیز عمل میکنند.
ریسک نوسازی را کاهش دهید
هرچه اطلاعات بیشتری دربارهی سیستم قدیمی داشته باشید، شگفتیهای کمتری در آینده خواهید داشت. با انجام خوب اکتشاف، شانس از دست دادن یک قاعده کسبوکار یا وابستگی حیاتی هنگام انتقال به سیستم جدید بهطور چشمگیری کاهش مییابد. در واقع، شما در حال روشن کردن تمام زوایای تاریک سیستم قدیمی هستید تا هیچ مشکلی در زمان نوسازی پنهان نماند.
برنامهریزی مرحلهای و تدریجی برای نوسازی
پس از شناسایی نیازها و الزامات، مرحله بعدی برنامهریزی برای نوسازی بهصورت مرحلهای و تدریجی است. این استراتژی یکی از مهمترین روشهای کاهش ریسک در نوسازی سیستمهای اصلی است:
از تلاش برای انجام همهچیز بهصورت همزمان خودداری کنید.
تقسیم بر اساس عملکرد کسبوکار
یکی از روشهای تقسیم نوسازی، شناسایی بخشهای مستقل از عملکرد است که میتوان آنها را بهصورت جداگانه نوسازی کرد. بهعنوانمثال، در یک سیستم بانکی، ممکن است با مهاجرت قابلیت جستجوی مشتری و پرسوجوی حسابهای پایه به یک میکروسرویس جدید شروع کنید، درحالیکه پردازش تراکنشها هنوز بر روی سیستم اصلی باقی میماند. اینگونه میتوان با یک بخش در هر زمان کار کرد و همزمان یاد گرفت.
الگوی خفهکننده
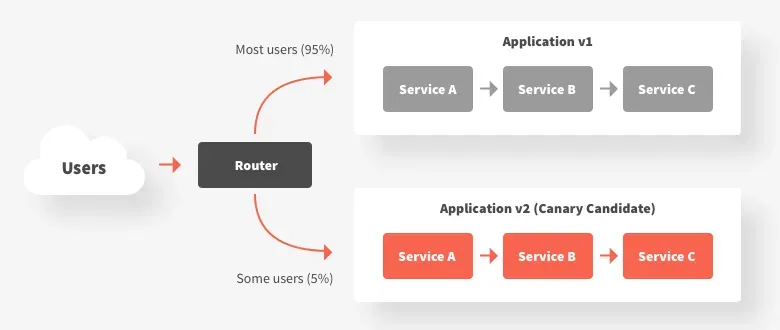
الگوی خفهکننده (Strangler Pattern) بهطور تدریجی سیستم قدیمی را از طریق مسیریابی جریانهای خاص به خدمات جدید در طول زمان نابود میکند. این الگو بهگونهای عمل میکند که تماسهای جدید بهطور انتخابی به سیستم قدیمی یا مؤلفه جدید هدایت میشود. بهمرور زمان، نقش سیستم قدیمی کاهش مییابد تا جایی که میتوان آن را خاموش کرد.
اجرا و انتقال تدریجی
یکی دیگر از رویکردها این است که سیستم جدید را در کنار سیستم قدیمی بسازید و برای یک دوره بهصورت موازی اجرا کنید. در ابتدا، سیستم قدیمی بهعنوان سیستم اصلی ثبت باقی میماند، اما سیستم جدید با ورودیهای مشابه تغذیه میشود تا بار را شبیهسازی کند و اطمینان حاصل کند که نتایج مشابهی تولید میکند. هنگامی که اطمینان حاصل شد، بهتدریج کاربران و تراکنشهای واقعی به سیستم جدید منتقل میشوند.
با استفاده از یک روش مرحلهای، ریسک بهطور چشمگیری کاهش مییابد: حتی اگر یک بخش کوچک شکست بخورد یا به تأخیر بیفتد، تمام پروژه غرق نخواهد شد و میتوانید فقط آن بخش را به حالت قبل برگردانید. این رویکرد همچنین فرصتهای یادگیری زودهنگام و پیروزیهای اولیه را فراهم میکند.
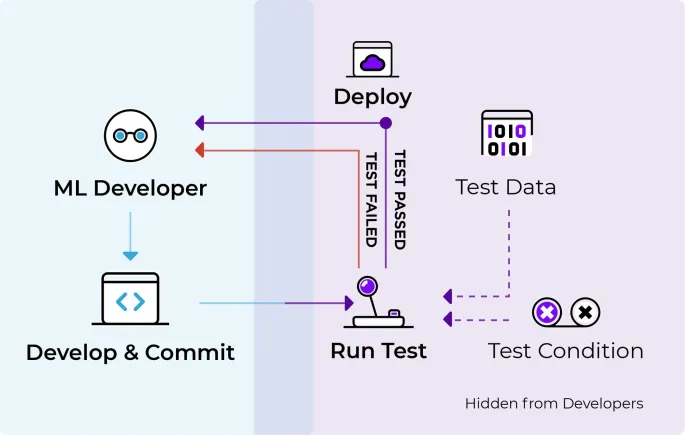
فرآیندهای تست و اعتبارسنجی دقیق
تست بهعنوان شبکه ایمنی شما برای شناسایی مشکلات قبل از تأثیرگذاری بر کسبوکار عمل میکند. برای نوسازی، این تنها به تست ویژگیهای معمولی محدود نمیشود، بلکه معمولاً شامل تستهای مقایسهای بین سیستم قدیمی و جدید است.
اتوماسیون موارد تست
با استفاده از اطلاعات بهدستآمده در مرحله شناسایی، یک مجموعه تست جامع ایجاد کنید که شامل موارد استفاده شناختهشده و موارد حاشیهای از سیستم قدیمی باشد. بهعنوانمثال، اگر سیستم اصلی محاسبه خاصی برای نرخهای بهره با دقت هفت رقم اعشار دارد، این سناریو را در سیستم جدید تست کنید. هدف، اطمینان از این است که خروجی پیادهسازی جدید با خروجی سیستم قدیمی برای همان ورودی مطابقت دارد، مگر اینکه تفاوت بهصورت عمدی باشد.
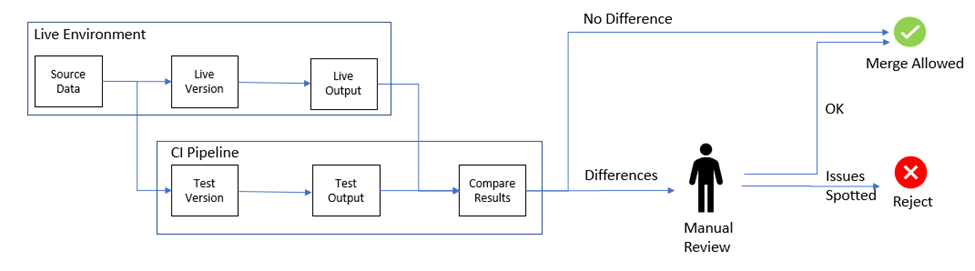
اجرای موازی و مقایسه
اگر امکانپذیر باشد، سیستم قدیمی و جدید را با ورودیهای یکسان بهصورت موازی اجرا کنید و نتایج را مقایسه کنید. هرگونه اختلاف یک علامت قرمز است که باید بررسی شود. این رویکرد میتواند تفاوتهای ظریفی را که ممکن است با ایجاد موارد تست دستی نادیده گرفته شوند، کشف کند.
تست بار و عملکرد
سیستمهای اصلی بهخاطر توانایی در مدیریت بارهای عظیم بهطور مؤثر شناخته شدهاند. پلتفرم مدرن شما باید ثابت کند که میتواند کارایی مشابه یا بهتری را ارائه دهد. تستهای استرس با حجمهای بالاتر از بار تولید اوج انجام دهید. نهتنها از نظر حجم، بلکه زمانهای پاسخ را نیز زیر نظر داشته باشید.
برنامهریزی برای بازگشت ایمن و برنامههای اضطراری
حتی با بهترین تستها، باید یک برنامه B داشته باشید. روز راهاندازی، چه اتفاقی میافتد اگر چیزی حیاتی خراب شود؟ برای این سناریو از پیش آماده شوید:
پنجرههای عملیاتی دوگانه
در نظر بگیرید که سیستمهای قدیمی و جدید را برای یک دوره اولیه بهصورت موازی اجرا کنید. به این ترتیب، اگر مشکلی کشف شود، میتوانید بهسرعت به سیستم قدیمی برگردید بدون اینکه نیاز به یک وقفه کامل باشد. این استراتژی به شما این امکان را میدهد که در صورت بروز مشکلات، از سیستم قدیمی بهعنوان پشتیبان استفاده کنید.
همگامسازی دادهها و پشتیبانگیری
یکی از چالشهای بازگشت به حالت قبل، انحراف دادهها است. اگر تراکنشهای جدیدی در سیستم جدید انجام شده باشد، چگونه میتوانید آنها را به سیستم قدیمی برگردانید؟ برنامهریزی برای این موضوع ضروری است.
سوئیچها
اگر ممکن است، سوئیچهایی برای روشن یا خاموش کردن برخی از قابلیتهای جدید پیادهسازی کنید. به این ترتیب، اگر یک جزء دچار مشکل شد، میتوانید آن را غیرفعال کنید درحالیکه بقیه سیستم جدید فعال است.
آموزش تیم و انتقال دانش
ریسک نوسازی تنها به کد محدود نمیشود، بلکه به افراد نیز مربوط میشود. برای کاهش ریسک از دست دادن دانش حیاتی، باید بهطور عمدی به مدیریت انتقال دانش و آموزش تیم بپردازید.
آموزش متقابل تیمها
توسعهدهندگان با تجربه را با کارشناسان فناوری مدرن در طول پروژه جفت کنید. این کار به هر دو طرف این امکان را میدهد که از یکدیگر یاد بگیرند و به کاهش وابستگی به یک فرد خاص کمک کند.
کارگاهها و دورههای آموزشی
اگر تیم شما دارای شکافهایی است، زمان مناسبی را برای برگزاری کارگاهها و دورههای آموزشی سرمایهگذاری کنید. حتی یک درک سطحی از “روش قدیمی” و “روش جدید” برای همه افراد درگیر، میتواند ارتباطات را تسهیل کند.
ایجاد دانش سیستم جدید زودهنگام
هنگامی که قطعات سیستم جدید ساخته میشوند، اطمینان حاصل کنید که تیم عملیات/پشتیبانی در حال یادگیری آنهاست. این کار به آنها اطمینان میدهد که در زمان راهاندازی، به خوبی آماده هستند.
حفظ تعادل بین قدیم و جدید در طول انتقال
در طول پروژه نوسازی، شما برای مدتی در یک حالت هیبریدی زندگی خواهید کرد — برخی از عملکردها بر روی سیستم قدیمی و برخی دیگر بر روی سیستمهای جدید. مدیریت این همزیستی بهطور دقیق اهمیت دارد.
حفظ ثبات سیستم قدیمی
ایدهآل این است که سیستم قدیمی در طول نوسازی تغییرات کمتری داشته باشد. بسیاری از تیمها یک “یخزدن کد” در سیستم قدیمی ایجاد میکنند، به جز برای اصلاحات حیاتی.
همگامسازی دادهها بین سیستمها
اگر هر دو سیستم قدیمی و جدید بهصورت موازی در حال اجرا هستند، اطمینان از انسجام دادهها ضروری است. بهعنوانمثال، اگر بهروزرسانیهای آدرس مشتری به سیستم جدید منتقل شوند، باید اطمینان حاصل شود که سیستم قدیمی نیز این تغییرات را دریافت میکند.
نظارت بر هر دو طرف
نظارت و گزارشگیری برای سیستم جدید و قدیمی در طول انتقال تنظیم کنید. بسیاری از مشکلات ممکن است در گزارشها بهعنوان عدم تطابقها ظاهر شوند.
نتیجهگیری
نوسازی سیستمهای اصلی هرگز کاملاً بدون ریسک نخواهد بود، اما با پیروی از استراتژیهای مناسب، میتوان ریسکها را به حد قابلمدیریتی کاهش داد. این به دانش، برنامهریزی و احتیاط بستگی دارد.
دانش: ناشناختهها را شناخته کنید. از مستندات و ابزارهای مناسب برای درک عمیق سیستمهای قدیمی استفاده کنید.
برنامهریزی: سفر را به مراحل امن تقسیم کنید. یک نقشه راه واضح، برنامه تست و گزینههای بازگشت داشته باشید.
ابزارها: ابزارهای مناسب را برای استفاده از هوش مصنوعی در نوسازی انتخاب و به کار ببرید تا آن را ایمنتر، سریعتر و ارزانتر کنید.
احتیاط در پیشرفت: نوسازی را در مراحل انجام دهید، اعتبار هر مرحله را بهطور دقیق تأیید کنید و در آنچه نباید عجله کنید، عجله نکنید.
با این رویکرد، نوسازی سیستمهای قدیمی به یک سفر موفق تبدیل خواهد شد و سازمانها میتوانند با اطمینان به آینده مدرن خود نگاه کنند.















.svg )




.svg )
.svg )